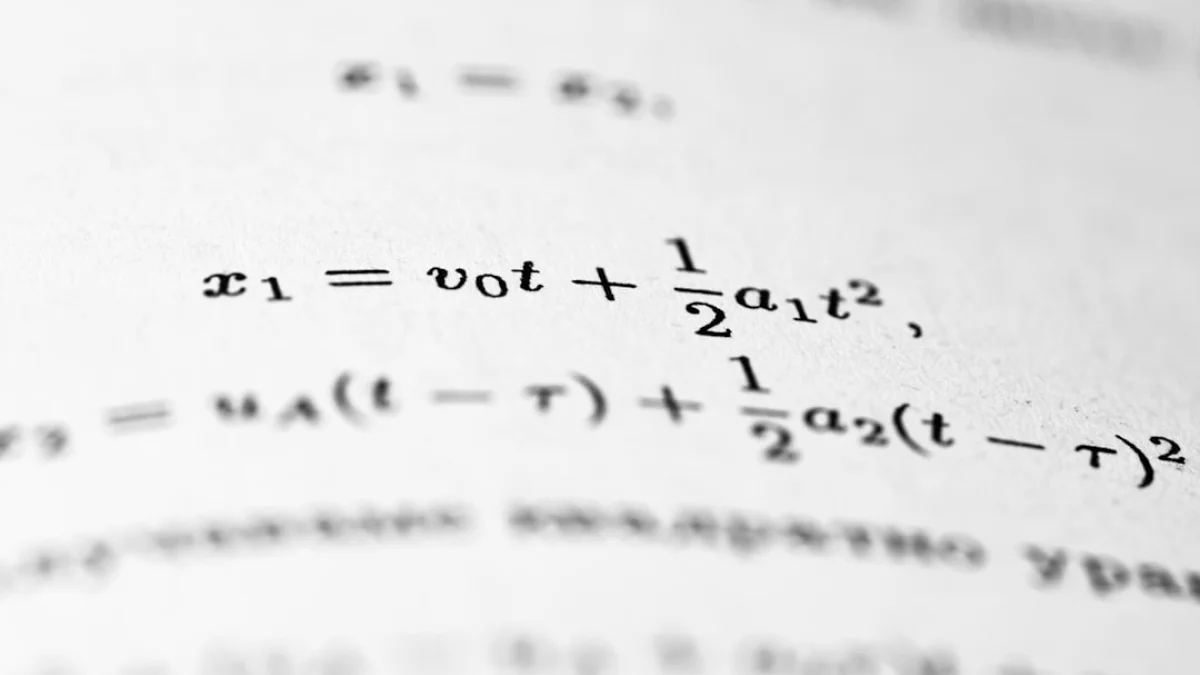GPT-5.2が切り拓く高難度数学の新時代

GPT-5.2とCodexの登場で高難度数学へのAI活用が一気に現実味を帯び、研究や教育では出力検証、セキュリティ、費用対効果の段階的検証が成功のカギになります。
導入部
難問を人とAIで分け合って解く時代が、本格的に始まりました。GPT-5.2の登場で、高難度の数学問題にAIが実用的な形で関わる光景が増えています。まるで暗闇を照らす灯台のように、AIは解法の見取り図や数値実験を素早く提示できますが、そこには慎重さも必要です。
GPT-5.2は何が変わったのか
GPT-5.2は、複雑な数式や論理のスケッチを生成する能力が高まりました。ここでいうGPT-5.2は、大規模な言語モデルで、文章や数式の生成に優れています。研究者は証明のアイデア出しや反例探索、数値検算の自動化などにAIを使い始めています。
しかし出力が常に正しいわけではありません。人間が検証するプロセスを前提に、AIが“アシスタント”として働くことが現実解です。出力の妥当性を透明に示す仕組みが欠かせません。
Responses APIとCodexの意義
OpenAIはGPT-5.2 CodexをResponses API経由で提供しています。Codexはコード生成やバグ検出に強いモデルです。これにより、数値実験の自動化や検算用スクリプトの生成が容易になります。
利点は生産性の向上とバグ発見の効率化です。一方で、従来より高い価格設定が報告されており、コスト管理は導入時の重要課題となります。
現場で気をつける点(実務的アドバイス)
出力の正確性と再現性の確保が最優先です。具体的には以下をおすすめします。
- 評価基準を定める:正しさ、再現性、実行速度などを定量化してください。
- 小規模で試す:無料トライアルやパイロットプロジェクトで性能を測定します。
- 自動テストを整備する:単体テストや数値検算で出力を検証します。
- 人間の査読を必須にする:最終的な論証や公表前には専門家の確認を入れてください。
- セキュリティとコストの見積もりを行う:API利用によるデータ流出リスクや長期コストを評価します。
これらは数学の研究でも教育でも共通の基本対策です。
倫理・法的な考慮も忘れずに
AIが作った補助手段の帰属や著作権、学術上の責任など、倫理的な問題は重要です。AIが生成したアイデアをどう扱うか、共同執筆や引用のルールを組織で整備してください。
また、AIの出力が誤っていた場合の検証責任を明確にしておくことも必要です。
これから試すべき戦略
短期的には出力検証体制を整え、小さなプロジェクトで効果を測ってください。中長期的には評価指標を磨き、社内外のガイドラインに従って段階的に導入を広げるのが安全です。研究開発の速度は確実に上がりますが、品質管理を置き去りにしないことが肝心です。
結びにかえて
AIは数学の助手として力を貸してくれます。けれども、その力を生かすには人間側の検証網が不可欠です。まずは小さく試し、学びながら拡大していく。そんな姿勢が、AIと共に難問に挑む現場の新しいスタンダードになるでしょう。