LLM の謎「コードは完璧、日常会話は破綻」——強化学習とタスク検証可能性の限界
LLM が複雑なコードタスクで優れている一方、日常的な質問に失敗する。この矛盾は検証可能性にある。報酬を得られる領域(コーディング・数学)では強化学習が機能するが、曖昧な領域では最適化が進まない。
最先端の言語モデルには奇妙な矛盾がある。数時間で膨大なコードベースを再構築し、セキュリティ脆弱性を検出するほどの能力を持ちながら、一方で日常的な質問には難なく失敗する。研究者の Andrej Karpathy は、「OpenAI の最高水準 Codex モデルはコードベース全体を再構造化したり、セキュリティの脆弱性を探出したりできるのに、高度な音声モード(Advanced Voice Mode)は最も簡単な質問でつまずく」と指摘している。
検証可能性が鍵
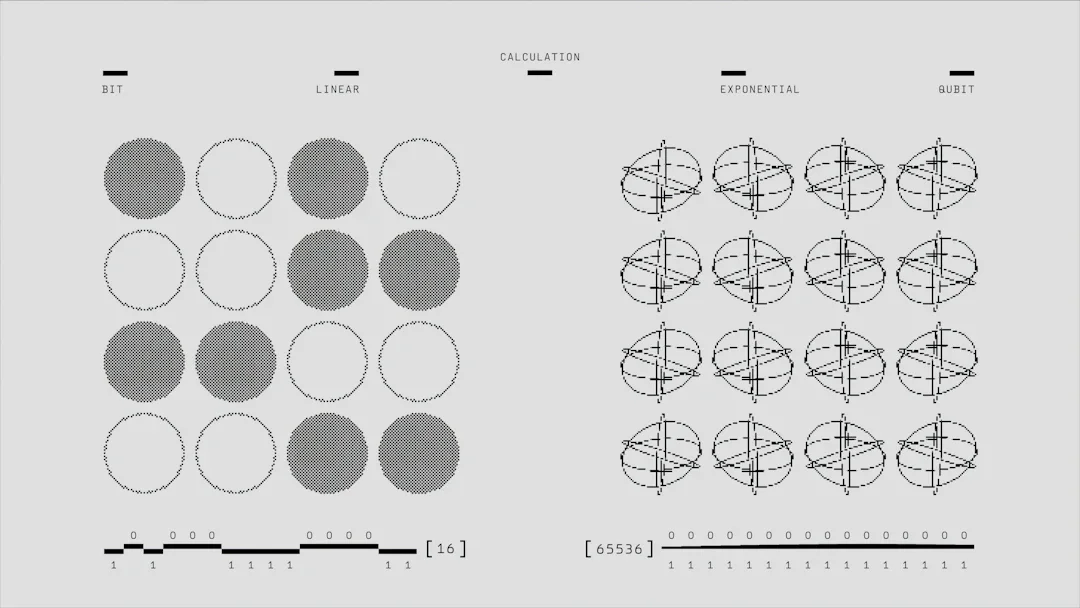
この現象の根源は「検証可能性」にある。正誤が明確に判定できるタスク——プログラミング、数学——は強化学習による報酬最適化の恩恵を受ける。対照的に、日常会話のような曖昧な領域には清潔な評価指標が存在せず、モデルの改善が進みにくい。
つまり、LLM は「答えの正否が自動検証できる領域」では驚異的に優秀だが、「複数の正答が存在する、あるいは正答そのものが定義できない領域」では性能が低迷する。
汎用知能への問い
この現象は根本的な問いを投げかける。言語モデルから汎用知能は生まれるのか、それとも領域特化の集合体に過ぎないのか。Karpathy の「Software 2.0」概念では、自動化の可能性は「結果が体系的に検証・最適化できるか否か」に依存するという。
現在のところ、汎域的な検証関数(universal verifier)による強化学習の拡張について言及する研究者もいるが、実装されたソリューションはまだ現れていない。今後、言語モデルの能力限界をどう超えるかは、このボトルネックをどう解決するかにかかっている。