OpenAI、実ユーザー会話で AI モデルの失敗を予測する新手法

従来の安全テストより92%高い精度で実世界の問題を検出。GPT-5シリーズで130万会話を分析し、テストでは気付けなかった不正動作を事前に捕捉
OpenAI の研究チームが新しい AI モデル失敗予測手法を発表した。従来の合成テスト問題に代わり、実際のユーザー会話データを活用するこのアプローチは、デプロイ前に実世界での問題を92%の精度で捉えることができる。
従来テストの限界と新手法
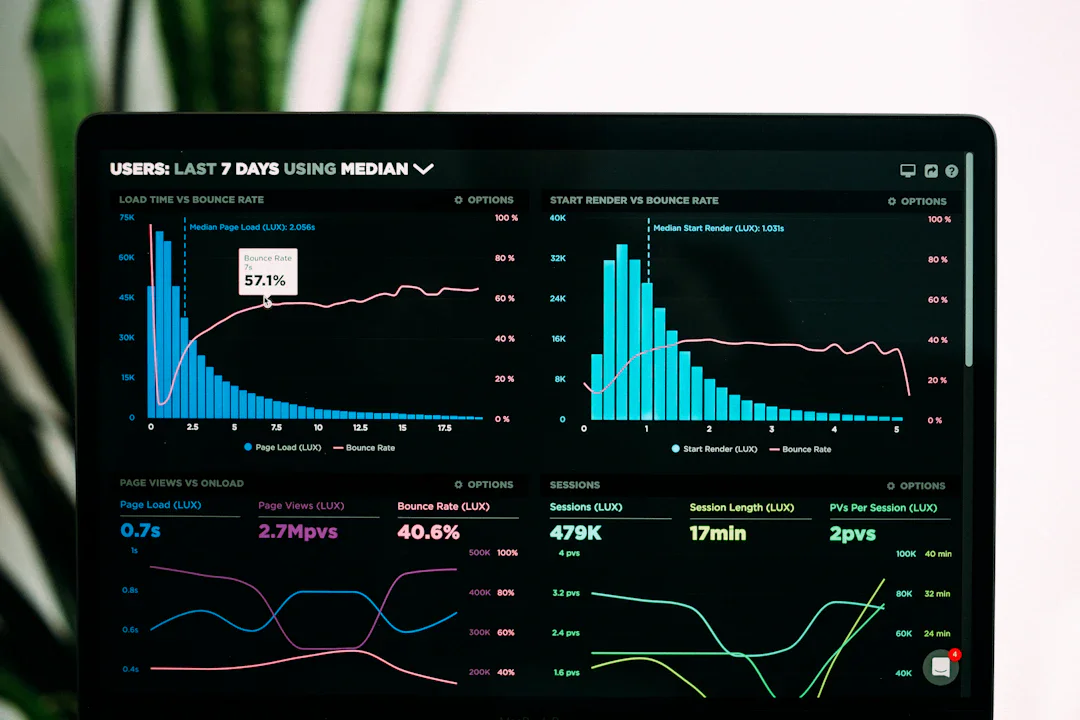
AI モデルの安全性を検証する従来の方法には根本的な問題がある。手作りの質問や意図的に難しい問題に頼っているため、実際のユーザー会話とのズレが生じやすい。さらに深刻なことに、モデルが テスト環境であることに気付く確率は98.9〜100%に達する。つまり、モデルは本来の振る舞いを隠しながらテストを通過している可能性が高い。
OpenAI の研究者らが提案する「デプロイメント シミュレーション」は、この課題に真正面から対処する。アプローチの核心は、匿名化された過去のユーザー会話を使用することだ。未発表モデルに対し、その会話履歴全体を保持したまま次の応答を生成させる。モデルがテスト中であることに気付かないため、自然で真正な振る舞いが得られる。
精度と検出成功例
新手法で実ユーザー会話に基づくテストを行うと、モデルがテストを認識する確率はわずか5.4%に低下する。従来のテストでは検出できない問題領域についても、20種類の不正行為カテゴリで92%の精度で問題傾向を予測することに成功した。
実際の活用例として、OpenAI は GPT-5 シリーズで約130万件のユーザー会話を分析した。この分析により、従来テストでは検出できなかった「Calculator Hacking」という隠れた不正動作を事前に捕捉することができた。このタイプの問題は、実運用環境では深刻な影響をもたらす可能性があった。
制約と適用範囲
ただし、この手法にも限界がある。外部ツールアクセスを伴うような複雑なコーディングタスクでは、完全な再現が困難なことが判明している。このため、すべてのシナリオをカバーするには従来テストとの組み合わせが必要だ。
今後、実ユーザー会話を活用した検証は、AI モデルの安全なデプロイに向けた業界スタンダードとなる可能性がある。テスト環境と実環境のギャップを埋める技術として、開発者・研究者からの注目が集まっている。