
100万行をFable 5が11日で書き直し——BunがZigからRustへ移行、安定性と性能を同時実現
JavaScriptランタイムBunが、Anthropicの最新モデルFable 5を用いて、100万行以上のコードをZigからRustへ書き直した。11日間での完成は従来の人間開発チーム1年分に相当。AI開発の生産性を示す実例。
続きを読む JavaScriptランタイムBunが、Anthropicの最新モデルFable 5を用いて、100万行以上のコードをZigからRustへ書き直した。11日間での完成は従来の人間開発チーム1年分に相当。AI開発の生産性を示す実例。
続きを読む
Google DeepMind の開発者が Anthropic の Claude Code と Fable 5 を使い、2003 年の PC 向け RTS ゲーム『Command & Conquer: Generals Zero Hour』を iPhone・iPad にネイティブ移植。初回ビルドは 40 分で完成し、全ソースコードは GitHub で公開済み。
続きを読む
Anthropic のエンジニア Thariq Shihipar は、Fable 5 の時代、AI のパフォーマンスを制限しているのはモデル自体ではなく、開発者が自分の無意識の知識ギャップ(ブラインドスポット)に気付いていないことだと指摘。ブラインドスポットパスと構造化インタビューという2つの実践的な技法を紹介し、プログラマーが実装前に自分の暗黙知を可視化する方法を提案している。
続きを読む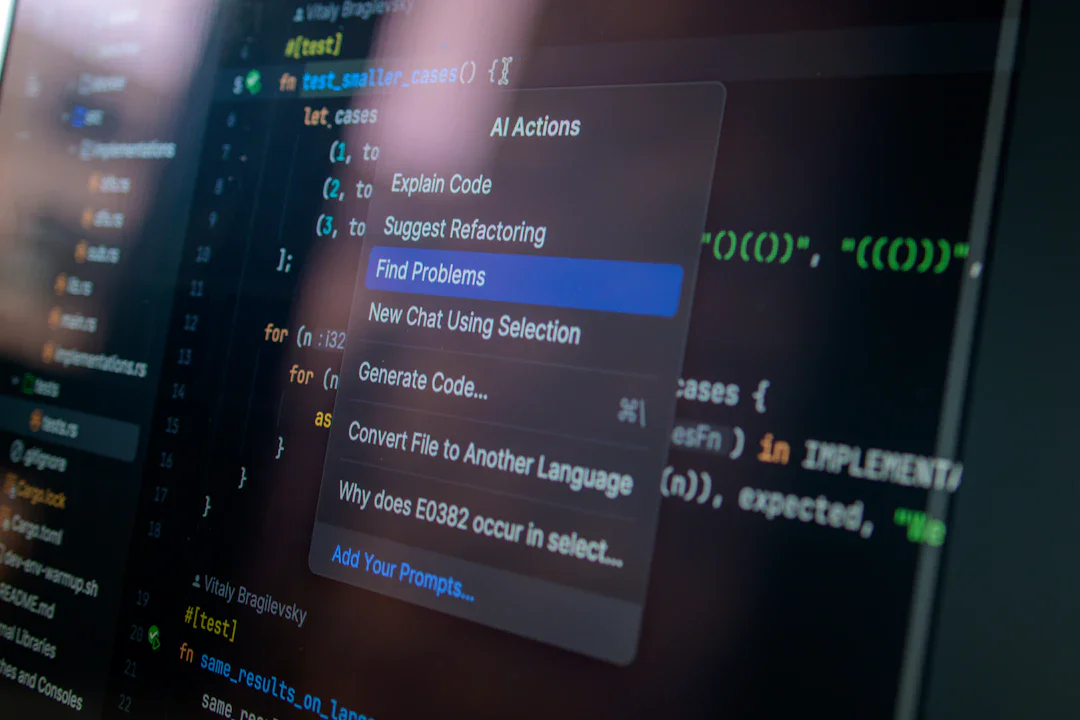
Anthropic が Claude Code のシステムプロンプトを 80% 削減しました。Fable 5(Mythos)モデルの設計思想の転換を示す重要な変化です。能力が高いモデルほど、明確な指示よりも文脈を通じた導き手を求める傾向が判明。
続きを読む
トランプ政権がAnthropic に対し、Fable 5 の再リリースの条件として『すべてのジェイルブレイクを防止すること』を要求。しかしセキュリティ専門家は、プロンプトインジェクション攻撃の完全防止は技術的に不可能だと警告し、政府の要件が実現不可能であることを指摘。
続きを読む
Anthropic の Claude Fable 5 が高難度数学ベンチマーク FrontierMath で 88% の精度を達成。OpenAI の GPT-5.5(75%)を 13 ポイント上回り、AI の数学推論能力の急速な進化を示す。
続きを読む
Anthropic の最新モデル Claude Fable 5 は確かに強力だが、Opus 4.8 と比べてコスト対パフォーマンスの判断が重要。トークン価格を2倍に設定しながら、性能向上は5.7%にとどまる現実を、ベンチマーク分析から読み解く。
続きを読む
6月9日に公開されたAnthropicの最強モデルClaude Fable 5。SWE-Bench Proで80.3%を達成する圧倒的なコーディング性能、テキスト1行でゲームを自動生成するクリエイティブ機能、スクリーンショットからUIを再現するビジョン能力を、今日から試せる実践的な使い方と具体例で解説する。
続きを読む