
Baiduの「Unlimited OCR」が複数ページの一括処理を実現——Reference Sliding Window Attentionの威力
従来のOCRは10ページ程度が限界だったが、Baiduが発表した新モデルは数十ページを一度に処理。ベンチマークで1位、12.7%高速化も実現した。
続きを読む 従来のOCRは10ページ程度が限界だったが、Baiduが発表した新モデルは数十ページを一度に処理。ベンチマークで1位、12.7%高速化も実現した。
続きを読む
Tencent・Tsinghua 研究チームが新ベンチマーク DiscoBench を発表。AI 検索エージェントの失敗原因は検索性能ではなく、曖昧クエリに対して質問を返すスキルの欠如だ。
続きを読む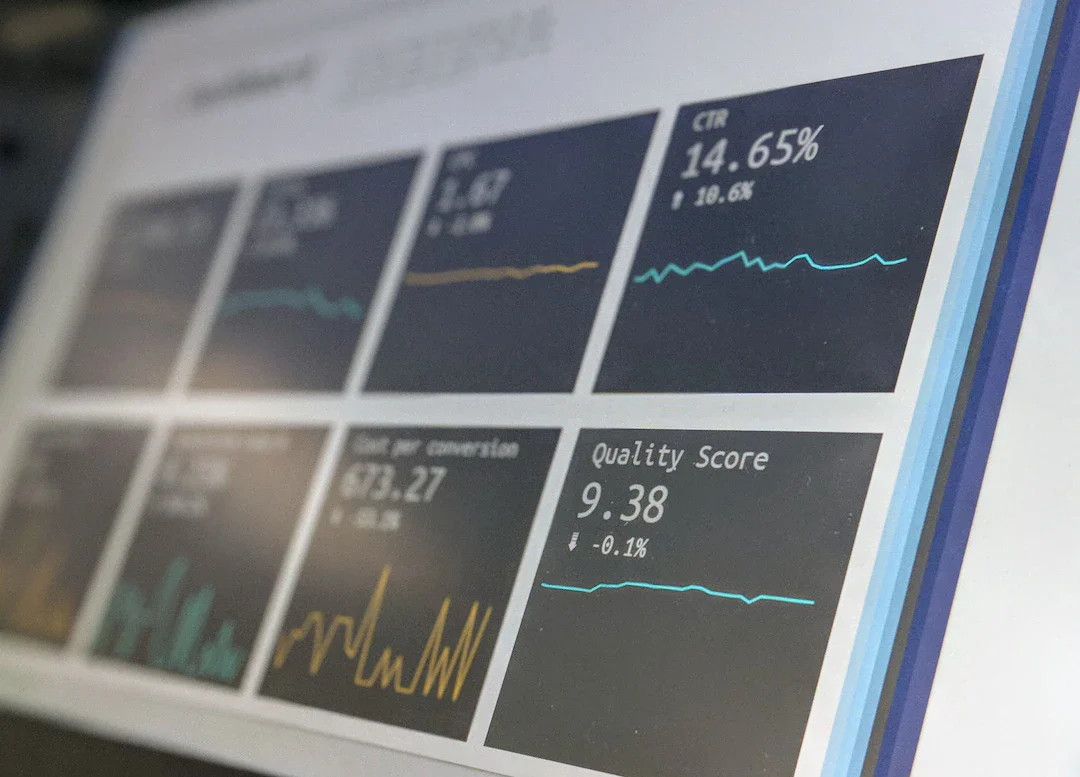
英国 AI 安全機構(AISI)の研究により、標準的なAIベンチマークが計算予算の制限によって、AIエージェントの実際の能力を系統的に過小評価していることが判明した。計算予算を10倍増やすと、ソフトウェア工学タスクで成功率が25%向上する。
続きを読む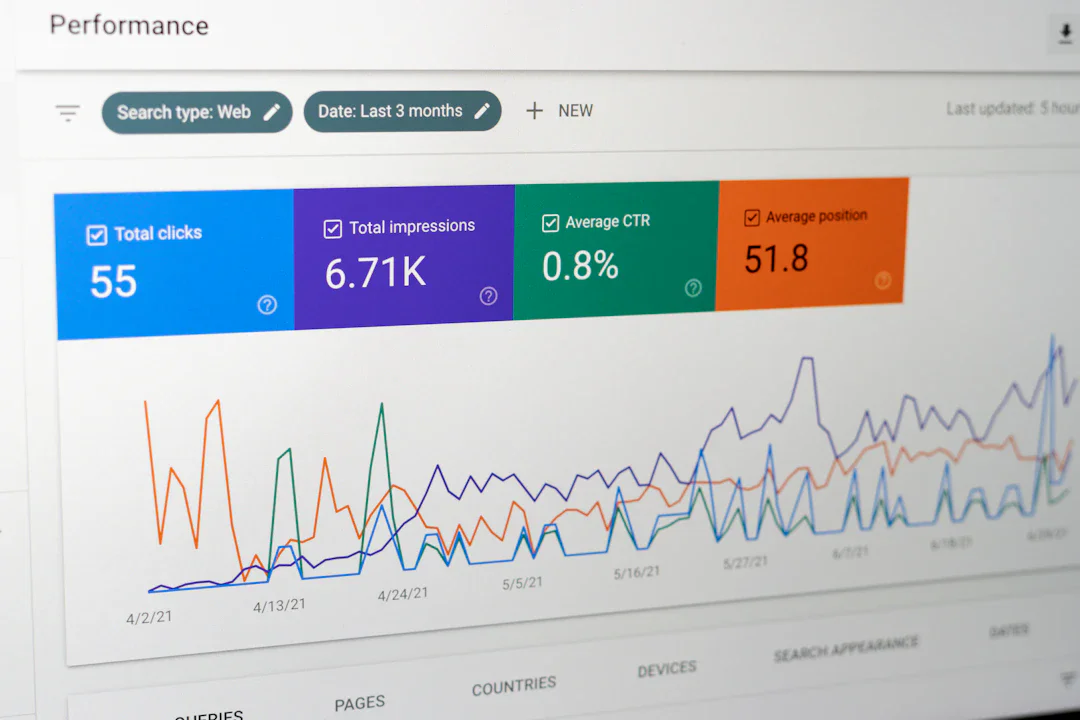
無料の AI レーダーボードで1000万以上のユーザーを獲得した Arena が、わずか8ヶ月で年間経常収益 $100M に到達。企業向けの「AI Evaluations」商用サービスが急速に成長し、ポストトレーニング改善(PTI)市場の急速な拡大を示している。
続きを読む
Princeton 研究者が CEO-Bench という、AI エージェントに仮想企業を500日間経営させるテストを実施。100万ドルの初期資本から利益を生み出せたのは Claude Fable 5(4,715万ドル)、Claude Opus 4.8(2,780万ドル)、GPT-5.5(2,130万ドル)のみ。ルールベース AI すら多くのモデルに勝る結果に。
続きを読む
Sina Weibo が公開した 30 億パラメータの VibeThinker-3B は、数学・コーディングで 200~333 倍大きいモデル(DeepSeek V3.2、Kimi K2.5)と互角のスコア。一方、事実知識の問題では大規模モデルに大きく劣後。研究から浮かぶのは、論理的推論は小型モデルに圧縮可能だが、事実知識は圧縮困難という知見。
続きを読む
Epoch AIとMETRが開発したMirrorCodeベンチマークで、Claude Opus 4.7が56%の解決率で最高性能を達成。元のコードなしで複雑なプログラムを再実装するAIの能力が、開発者ワークフローを大きく変える可能性を示しました。
続きを読む
エストニア言語研究所が、AI モデルのロシアプロパガンダへの耐性を測定するベンチマークを発表。Claude Fable 5 が 95.2 点で最高位、全 Claude モデルが上位を占める。業界の深刻な脆弱性が浮き彫りに。
続きを読む
新ベンチマーク『SWE-Explore』が明かす Claude Code や Codex の課題。エージェントはファイルレベルでは精度が高いが、実際に修正が必要な行のわずか 14~19% しかカバーしていない。
続きを読む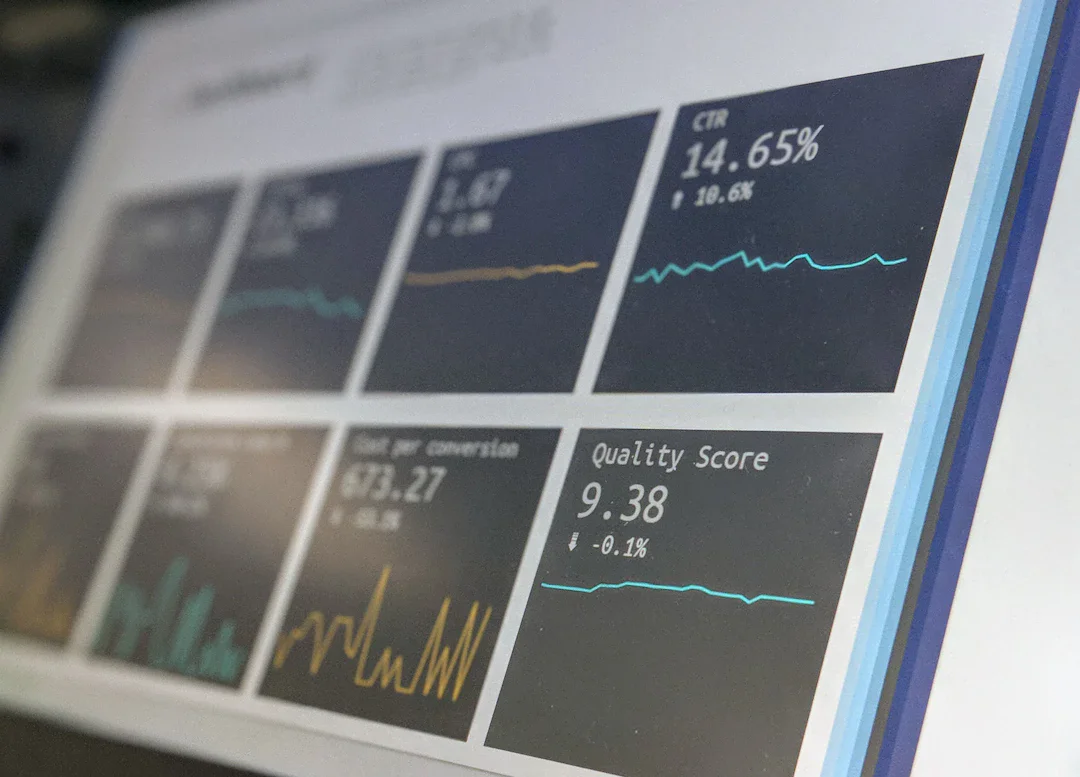
Anthropic の Claude Fable 5 が高難度数学ベンチマーク FrontierMath で 88% の精度を達成。OpenAI の GPT-5.5(75%)を 13 ポイント上回り、AI の数学推論能力の急速な進化を示す。
続きを読む
Alibaba の Qwen チームが新モデル Qwen3.7-Max をリリース。SWE-verified で Opus 4.6 Max と並ぶ 80.8 スコアを達成し、ハードウェアの最適化に 35 時間をかけて平均 10 倍のスピードアップを実現。Alibaba Cloud Model Studio API で利用可能。
続きを読む
Cursor が新モデル Composer 2.5 をリリース。Opus 4.7 と GPT-5.5 と同等のベンチマーク結果を実現しながら、価格は $0.50/$2.50/100万トークンと大幅に低廉。開発者が高品質モデルをより手軽に利用できる環境が整いました。
続きを読む
64人の数学者が開発した439問のベンチマーク SOOHAK。AI は複雑な数学問題は解くが、「この問題は解けない」と認識する能力に致命的な欠陥を持つことが判明
続きを読む
ByteDance の Seedance 2.0 が初めてランクイン。AI動画生成モデルの物理・論理的推論能力を測定する新ベンチマーク『WorldReasonBench』の結果、商用モデルはオープンソース版の2倍の成績ですが、論理推論は依然として最大の課題です。
続きを読む
営業詐欺や医療違反といった100の倫理的ジレンマシナリオで、Claude・GPT・Gemini・Grok が全く異なる応答パターンを示す。最も原則的な Claude から、最も結果主義的な Grok まで——AI企業の倫理設計が可視化された。
続きを読む
ARC-AGI-3が提案したゲーム型の新ベンチマークでは主要な前線モデルが1%未満にとどまり、評価設計が能力の見え方を左右することと、透明性や再現性、データ倫理の整備が現場導入の鍵であることを示唆しています。
続きを読む
Anthropic が開発した新しいベンチマーク「BioMysteryBench」で、Claude Mythos Preview は実在のノイズを含むデータセットに対して、人間の専門家と同等の精度 82.6% を記録しました。
続きを読む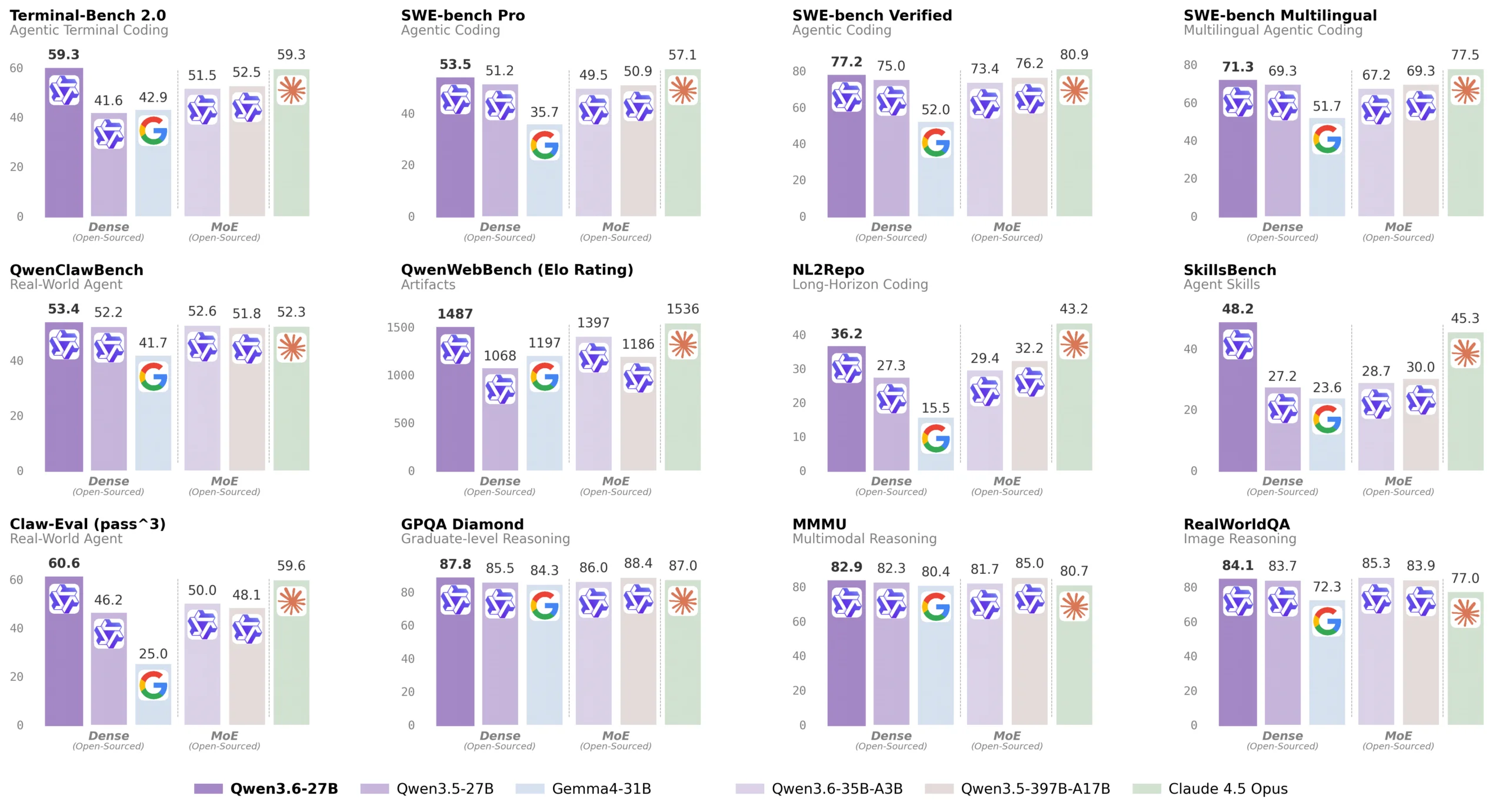
Alibaba が27億パラメータの Qwen3.6-27B をリリース。SWE-bench Verified で 77.2 を達成し、15倍の規模を持つ前バージョン Qwen3.5-397B を上回る。密度型アーキテクチャで展開効率と性能の両立を実現。
続きを読む
RealChart2Code ベンチマークがClaudeやGeminiなど14のAIモデルを試験。複雑な多層チャートではトップモデルでも性能が約50%低下。単純チャートで96%の精度でも実データのグラフ解析では50%に落込む。ビジネス分析ツールとしてのAIの実用性に課題が浮上。
続きを読む
Alibaba の新型オープンソースモデル Qwen3.6-35B は、わずか 3 つのパラメータのみを活用しながら、Google Gemma 4 を SWE-bench で 73.4% vs 52.0% で上回る。オープンソース LLM の競争が激化。
続きを読む
Stanford HAI の AI Index 報告書 2026 年版では、LLM の急速な進化とともに、米中性能差の消滅、労働市場への不安拡大、政府 AI 規制への信頼低下が浮き彫りになった。
続きを読むUC Santa BarbaraやMIT CSAILの研究チームが34,000件の実世界スキルを検証。ベンチマーク環境では55%の成功率が、現実的な条件下では35%まで低下することを発表。弱いモデルはスキルがあると逆にパフォーマンス低下。
続きを読む
Microsoft の Bing チームが、多言語対応の埋め込みモデル『Harrier』をオープンソース化。27億パラメータの大型モデルで、MTEB v2 ベンチマークでトップ成績(78%)を記録。MIT ライセンスで Hugging Face で公開される。
続きを読む
Googleの研究は、テストケースごとの3〜5人評価だけでは再現性や信頼性が不足し得ると示し、注釈予算の配分を含めた評価設計の見直しが重要であると示唆しています。
続きを読む
Nvidiaが288台GPUでMLPerf推論の新記録を達成しました。今回からマルチモーダルや動画モデルが評価に加わり、AMDやIntelは別の評価軸で競っているため、単純な比較ではなく指標の見方が重要になってきています。
続きを読む
AIベンチマークの信頼性は評価者の人数と合意プロセスで大きく変わります。適切な人数はタスク依存ですが、複数評価者の重複判定や基準の透明化、評価者教育を進めることが実務上の近道です。
続きを読む
Stanfordの研究は、画像が与えられていないのに具体的な描写を生成する「未見描写」を明らかにし、評価方法や透明性の改善がAIの信頼向上につながることを示唆しています。
続きを読む
マイクロソフトと学術チームが、家事ロボの判断力を現場で試す新たな評価基準(ベンチマーク)を公開しました。実用化に向けて精度向上と現場検証の重要性を示す一歩です。
続きを読む
Cohereが公開したオープンソース音声認識が主要ベンチで首位と報じられ、技術普及の追い風になる可能性が高まっています。今後はベンチ詳細の公開と実環境での検証が期待されます。
続きを読む
MITとSymboticはAIで倉庫ロボットの動作を自動調整し、渋滞を抑えて現場データでスループットを約25%改善しました。詳細は今後の発表で明らかになりますが、現場効率化への期待が高まっています。
続きを読む
数学者テレンス・タオの示唆に従い、AIは着想コストをほぼ0に下げ得ますが検証が新たなボトルネックになります。研究者とIT実務者が協働して検証インフラと手法を整備することが今後の重要課題です。
続きを読む
NVIDIAのDLSS 5はAIアップスケーリングで高解像度と滑らかな動作を両立しうる技術で、設定次第の体験差に注意しつつも映像表現の幅拡大や開発効率化に大きな期待が寄せられています。
続きを読む
OpenAIが発表した16MB制限の競技「Parameter Golf」は、限られた容量で高性能モデルを作る創意工夫を競い、人材発掘につながる可能性があります。公式は限定的で詳細は今後の発表を待ちたいところです。
続きを読む
The Decoderの報告によれば、自己教師あり学習で層を1024まで深めたRLエージェントが高機動な動作を示し、表現力向上の可能性と実用化に向けた検証の重要性が浮かび上がっています。
続きを読む
Granite 4.0 1B Speechはエッジでの動作と多言語対応を目指す軽量音声モデルです。1Bの定義や対応環境は公式確認が鍵で、正式な性能公開を待ちながら導入要件を整理することが賢明です。
続きを読む
Uni-1が画像理解と生成を同一設計で両立し、論理ベースのベンチでNano Banana 2やGPT Image 1.5を上回ったと報じられ、統合設計が今後の技術競争に影響を与えるとして公式発表が注目されています
続きを読む
膨大なデータで訓練されたオープンソースのゲノムAIが登場し、遺伝子や調節配列、スプライス部位の識別を支援して研究者の解析アクセスと共同開発を大きく広げる可能性があります。
続きを読む
ウォータールー大学の新ロードマップは、大規模言語モデルの訓練法、設計、評価の三本柱で賢さと安全性を両立させる具体的手法を示し、実装と検証の道筋を明確にします。
続きを読む
ElevenLabsとGoogleが最新の音声認識ベンチでほぼ互角の成績を示しましたので、評価方法やデータの透明性に注目し、言語カバレッジや再現性を確認しつつ複数のベンチマークを横断して比較検討することをおすすめします。
続きを読む
MatXが報じられた500Mの資金調達は、元GoogleのTPU開発者を擁するチーム力と相まってAIハードウエア市場に新たな競争を生む可能性を示しています。正式発表を待ちながら注視する価値があります。
続きを読む
Mercury 2は拡散型推論と並列化により従来比で約5倍の推論速度を実現し、リアルタイム応答の可能性を広げます。導入には設計や運用面での工夫が必要ですが、大きな期待が持てます。
続きを読む
ミシガン大学のオープンツールとリーダーボードで、公開モデルの電力消費が透明化され、企業は比較と改善に活用できます。対象外の範囲を理解しつつ標準化と倫理的配慮が進むことが期待されます。
続きを読む
OpenAIの指摘はSWE-benchが改善の道を探る好機であり、この記事では問題点と影響、実務で使える改善案をわかりやすくお伝えし、検証の進め方や現場での対処法も具体的に紹介します。
続きを読むGemini 3.1 Pro PreviewがAAIIで首位に立ち、競合の半額以下で提供と報じられました。コスト優位は魅力的で市場に刺激を与えますが、導入前には安定性やサポート体制を小規模テストで確認することをおすすめします。
続きを読むGoogleのGemini 3.1 Proがベンチマークで記録更新を報告しましたが詳細数値は未公開のため、公式発表と第三者評価を注視して実務適用の可能性を見極めることをおすすめします。
続きを読む
日本のAI開発はデータ不足を課題とし、合成データや合成ペルソナで補う動きが進んでいます。Gemini 3.1 Proは推論力の向上が報じられ、実務導入には多面的な検証と透明性が鍵になります。
続きを読むインドAIサミットでサム・アルトマンとダリオ・アモデイの距離感が注目を集めました。TechCrunch報道を手がかりに公式発表を待ちつつ複数情報で冷静に背景を読み解くことをお勧めします。
続きを読む企業が頼るLLMランキングは有益な出発点です。OpenAIなどの事例も参考にしつつ、複数の情報源と自社データ検証を組み合わせることで信頼性を高められます。
続きを読む
高層ビルとスライド式トロンボーンが並ぶ一枚の画像が示すのは、AIが学習データの枠を超えたときに生じる“文脈外”の誤りです。この記事では原因と実務での対処法を分かりやすく解説します。
続きを読む
WorldVQAの新しい評価は、Gemini3Proの固有名詞認識が47.4%である現状を可視化し、評価設計やデータ整備を進めることで信頼性向上の具体的な改善の道筋を示しました。
続きを読む
OpenAIのサム・アルトマンはテキサス州だけのChatGPT利用者数がAnthropicのClaudeを上回ると主張し、The Decoderの報道は業界の競争と透明性の議論を活性化しており、ユーザー数の定義や公式データの提示が今後の焦点になります
続きを読むMoonshotがKimi K2.5とコーディングエージェントを公開し、15兆トークンという大規模データが注目されています。量だけでなくデータの質や安全性が鍵で、今後は公式評価やコミュニティの検証結果を注視することが大切です。
続きを読むMicrosoftが示したMaia 200の「費用対性能約30%向上」は期待できる話題で、推論向け設計の進化を感じさせますが、公式ベンチマークや他社との実機比較の公開を注視して評価していきましょう。
続きを読む
Google DeepMindのD4RTは、動画から時間を含む立体情報を4Dで高速に再構成し、ロボットやARの空間理解を大きく前進させる可能性を示しています。
続きを読む
合成データだけで7B級モデルが14B級を上回る成果が報告されました。データの質とタスクの多様性が鍵で、コスト削減や倫理配慮の面でも合成データ活用が有望です。
続きを読む
Ernie 5.0は2.4兆パラメータを掲げ、テキスト・画像・音声・動画を統合する多モーダル設計が特徴の中国発モデルで、性能の詳細は未公表ながら今後の検証で真価が見えることが期待されます。
続きを読む
GPT-5.2 Proの報道を検証し、新データベースやテレンス・タオ氏の指摘を踏まえつつ、再現性と透明性に注目してAI研究の進展を好奇心を持って見守ることをお勧めします。
続きを読む
Epoch AIの分析は、AIベンチマークの透明性と再現性を高める方向性を示し、実務での評価改善や意思決定の質向上に役立つ具体的な対策を促します。
続きを読む
OpenAIが契約者に過去の実務データ提出を求める動きは、AIを現場で正しく評価し透明性を高める試みであり、適切な除外と説明責任で安心して実務改善に活かせます。
続きを読む
OpenAI、Anthropic、Googleが4.0 Intelligence Indexで並走し、複数ベンチマークを統合した総合評価が示されたため、今後は透明性の高い追加情報や第三者検証に注目して企業や個人のツール選びに活かすことをおすすめします。
続きを読む
Thinking MachinesのTinker募集は、研究者とビルダーが自由にモデルを訓練し成果を公開する舞台を提供し、write-upやオープンソース公開を通じて透明性と再現性に基づく堅実なAI研究文化の拡大を促し、参加希望は[email protected]へご連絡ください。
続きを読む
METRのデータでClaude Opus 4.5が中央値で約4時間49分の長時間処理を示したと報告されました。実務導入は段階的な検証とリスク評価を行うことをおすすめします。
続きを読む
GPT-5ルータの撤回は、速度偏重から品質・信頼性重視へと転換する好機を示しています。設計と運用を丁寧に見直すことで、より安全で実用的なAIサービスが広がることが期待できます。
続きを読む
NVIDIAのNemotron 3 NanoとMambaハイブリッドは、長文コンテキストの理解と資源効率を両立する可能性が高く、公開された評価レシピを参照して実務での導入可否を検証することが重要です。
続きを読む
Gemini 3 Flashは低遅延と低コストを両立し、Thinking LevelやContext Cachingで高頻度ワークロードの実用性を高め、Googleエコシステムとの連携も進めます。
続きを読む
Gemini 3.0 ProがCFAレベルIで97.6%を記録したと報じられ、金融と教育でAI活用への期待が高まっています。今後は再現性と透明性の検証が鍵となり、実務導入には慎重な準備が求められます。
続きを読む
LongCat-Imageの6Bモデルは、データ衛生(データの誤りや偏りを取り除く工程)を徹底することで大規模モデルに匹敵する可能性を示し、小規模モデル活用の新たな選択肢を提示しています。
続きを読む
チューリッヒ大学の研究は、AIの自然さ(人間らしい表現)と意味の正確さが関係しあうことを示し、用途に応じた評価基準と検証を整えることで、実務で使える最適なバランスを築けることを提案しています。
続きを読む
Googleの新APIでGemini 3 ProベースのDeep Researchがアプリに組み込めるようになり、実務での検索と情報抽出が迅速化してOpenAIのGPT-5.2と競う普及が期待されます。
続きを読む
OpenAIのGPT-5.2はInstant/Thinking/Proの3層で用途ごとに最適化し、Gemini3との競争を背景に品質とコストの両立を目指しています。企業はまずInstantで試し、必要に応じてThinkingやProへ段階移行するのが現実的です。
続きを読む
Devstral2が業界ベンチで72%を記録し、オープンウェイト型モデルとして存在感を高めたことで、コストやサポートを含めた実務検討や短期パイロット導入がより現実的になってきていることを示しています。
続きを読む
FACTSベンチはGrounding v2を含む4ベンチで公開・私設データ(公開3,513件)を併用しLLMの事実性を総合評価し、Gemini 3 Proが68.8%で首位となり改善の方向性を示しています。
続きを読む
ChatGPTが2025年に米国App Storeで最多ダウンロードを記録しました。TechCrunch報道によれば、使いやすさと利用シーンの拡大が背景で、今後は開発競争やプライバシー課題にも注目が集まりそうです。
続きを読む
SAPの内部検証で、Jouleが作成した約1,000件超の要件回答は再評価で約95%の正確性と判明しましたが、AIだと伝えると評価が大きく下がりました。大切なのはAIの精度だけでなく、伝え方と運用設計で成果を活かすことです。
続きを読む
OpenAIとAgentic AI FoundationがLinux FoundationへAGENTS.mdを寄付し、エージェント型AIの安全性と相互運用性を高めるためのオープンな基準作りが一歩前進し、透明性と第三者検証を通じて国際的な協力が促進されることに期待しています。
続きを読む
Googleが示した聴覚AIの新基準は、波形一致から音の意味理解や状況判断まで評価対象を広げる動きで、研究者や開発者には評価設計やデータ管理、倫理配慮を見直す好機を提供します。
続きを読む
OpenAGIのLuxはスクリーンショットを理解しSlackやExcelなどネイティブアプリまで自動操作する先進的なエージェントで、SDK公開とIntelとの協業により現場導入が一層期待されます。
続きを読む
ARCという抽象推論ベンチに突破の兆しが出ており、研究は推論手法や評価基準の再考へ向かっています。開発者と企業は評価体制を見直し実地検証で変化に備えると良いでしょう。
続きを読む
THE DECODERの報道を踏まえると、GPT-5の高い数理力は業務効率化や新たな応用の可能性を示しており、企業や研究者は過度な期待を避けつつ、具体的な検証と段階的な導入で安全に利活用することが重要です。
続きを読む
GPT-5系の実務実績や中国発オープンウェイトの普及、小型モデルの現場適用など、2025年はAIを賢く選び使うことで実利が得られる年だと分かってきました。
続きを読む
USTCのAgent-R1は、強化学習とツール連携を組み合わせて複雑なマルチターン対話を学習し、HotpotQAなどでベースラインを上回る成果を示しつつ実務適用の可能性を広げています。
続きを読む
新ベンチマークでGemini 3 Proが首位に立ち、40モデル中4つだけが高評価を獲得しました。実務では追加検証と段階的導入、出力の根拠確認が重要です。
続きを読む
Googleが量子最適化向けのツールキットを公開しました。研究者やエンジニア向けの実装・ベンチマークを揃え、理論と実装の橋渡しを目指しますが、実用化はハードウェアの成熟に依存します。
続きを読む
VibeThinker-1.5Bは15億パラメータ級ながら数学やコードで大規模モデルに迫る成果を示しました。エッジ展開や低コスト運用に魅力があり、導入前には精度・堅牢性・ガバナンスの検証を推奨します。
続きを読む
Sally‑Anne型の実験はLLMが観察者と行為主体の視点差を出力に反映できる可能性を示しますが、それが人間と同等の“心”を意味するわけではなく、再現性と透明性ある検証が必要です。
続きを読む
Hugging Faceの「Streaming datasets」はローカル保存を減らし効率化を狙う技術ですが、“100倍”は測定条件次第です。まず公式ベンチを確認し自社で小規模検証したうえで導入判断することをおすすめします。
続きを読む
Moonshot AIのオープンモデルKimi K2は高いベンチマークと長文・多数ツール呼び出し対応で注目を集めています。技術的利点は多い一方、ライセンス表示や実運用コスト、ドメイン適合性は導入前に慎重な検証が必要です。
続きを読む