Alibaba Qwen3.6-27B、15倍大きな前バージョンを圧倒――パラメータ効率で新基準
Alibaba が27億パラメータの Qwen3.6-27B をリリース。SWE-bench Verified で 77.2 を達成し、15倍の規模を持つ前バージョン Qwen3.5-397B を上回る。密度型アーキテクチャで展開効率と性能の両立を実現。
27 億パラメータで 15 倍大きなモデルを超える
Alibaba が新型のオープンソース言語モデル Qwen3.6-27B をリリースした。このモデルが示すのは、パラメータ数と実際の性能が必ずしも相関しないという、AI開発における新たな現実だ。
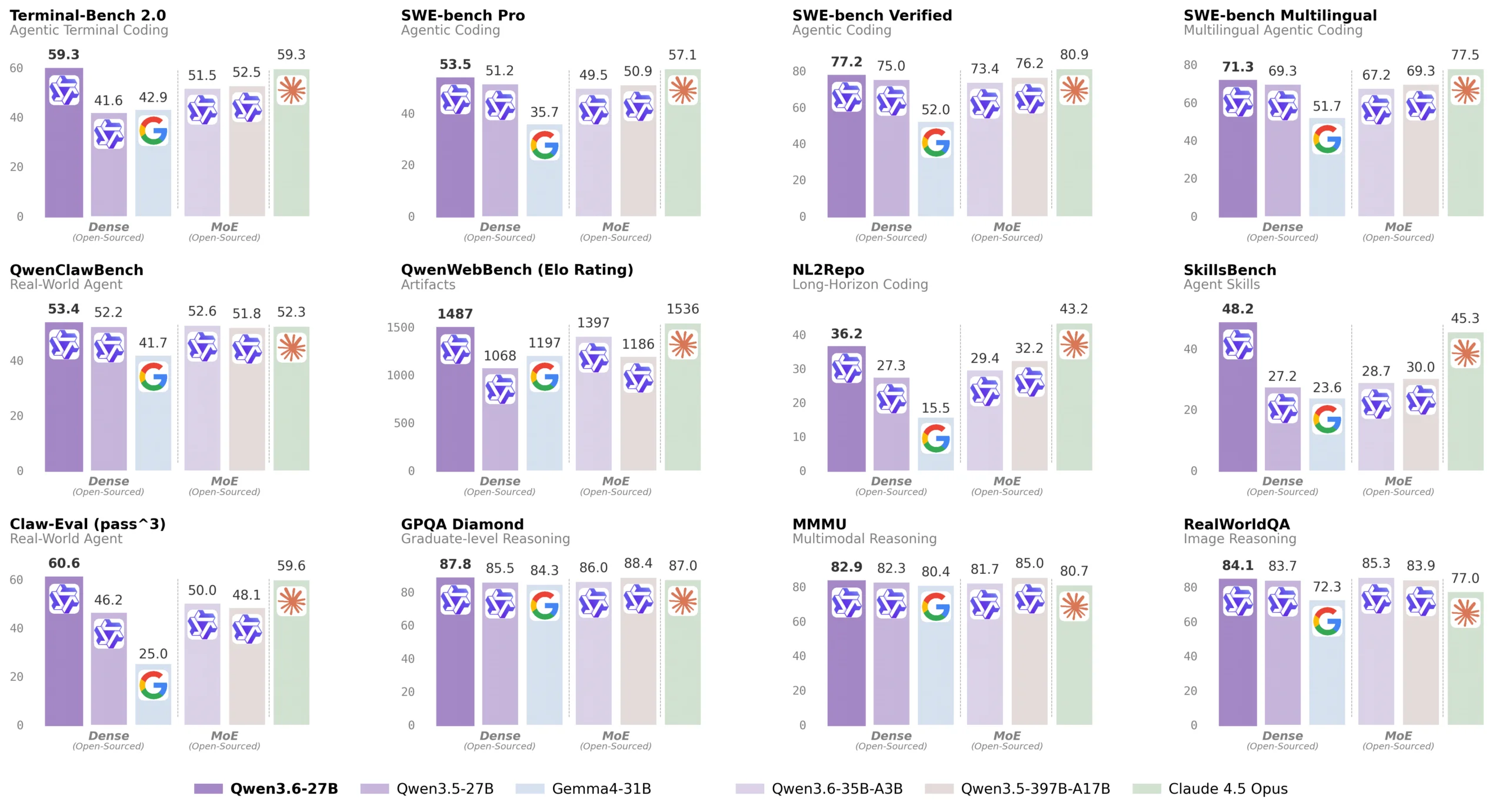
Qwen3.6-27B は SWE-bench Verified で 77.2、Terminal-Bench 2.0 で 59.3 を達成。これを前バージョンの Qwen3.5-397B と比較すると、その規模は前者が約 397 億パラメータに対して、新モデルは 27 億と 1/15 の規模 にもかかわらず、ほぼすべてのコーディングベンチマークで勝利している。
前バージョンのスコアは SWE-bench で 76.2、Terminal-Bench で 52.5 であったため、わずか 27 億パラメータの新モデルがこれを明確に上回る結果となった。
密度型アーキテクチャが展開効率を大幅改善
Qwen3.6-27B の強みは、モデルのアーキテクチャ設計にある。Mixture of Experts(MoE)ではなく、密度型の全結合型アーキテクチャ を採用している。
MoE は条件分岐によって計算効率を高める手法として広く用いられているが、推論インフラの複雑化を招く。一方、Qwen3.6-27B の密度型設計は、展開・運用の簡潔性を保ちながら、高い推論品質を実現する。
このアプローチは、エッジデバイスやリソース制約環境での利用を想定した設計思想を反映しており、Alibaba がオープンソースコミュニティ向けに実用性の高いモデルを目指していることを示唆している。
マルチモーダル推論でも Claude 4.5 Opus と競争
Qwen3.6-27B の適用範囲はコーディングに留まらない。GPQA Diamond や MMMU といったマルチモーダル推論ベンチマークでも、Claude 4.5 Opus と競争水準の性能を示している。
このことは、わずか 27 億パラメータのモデルが、Anthropic の最新鋭モデル(数十倍以上の規模)と同等の推論能力を備えていることを意味する。
アーキテクチャの進化がもたらす競争軸の変化
LLM 市場ではこれまで「パラメータサイズが大きい=性能が高い」という仮説が支配的だった。しかし Qwen3.6-27B が示すのは、効率的なアーキテクチャ設計と訓練データの最適化 によって、パラメータ数の劇的な削減が可能であるということだ。
これは AI 開発における新たな競争軸を生み出す。単なる「大規模化」ではなく、「いかに少ないパラメータで高い性能を引き出すか」という効率重視の設計思想が、今後の業界標準になるかもしれない。