Alibaba Qwen3.6 が Google Gemma 4 をコーディングベンチマークで圧倒——Mixture-of-Experts で効率化

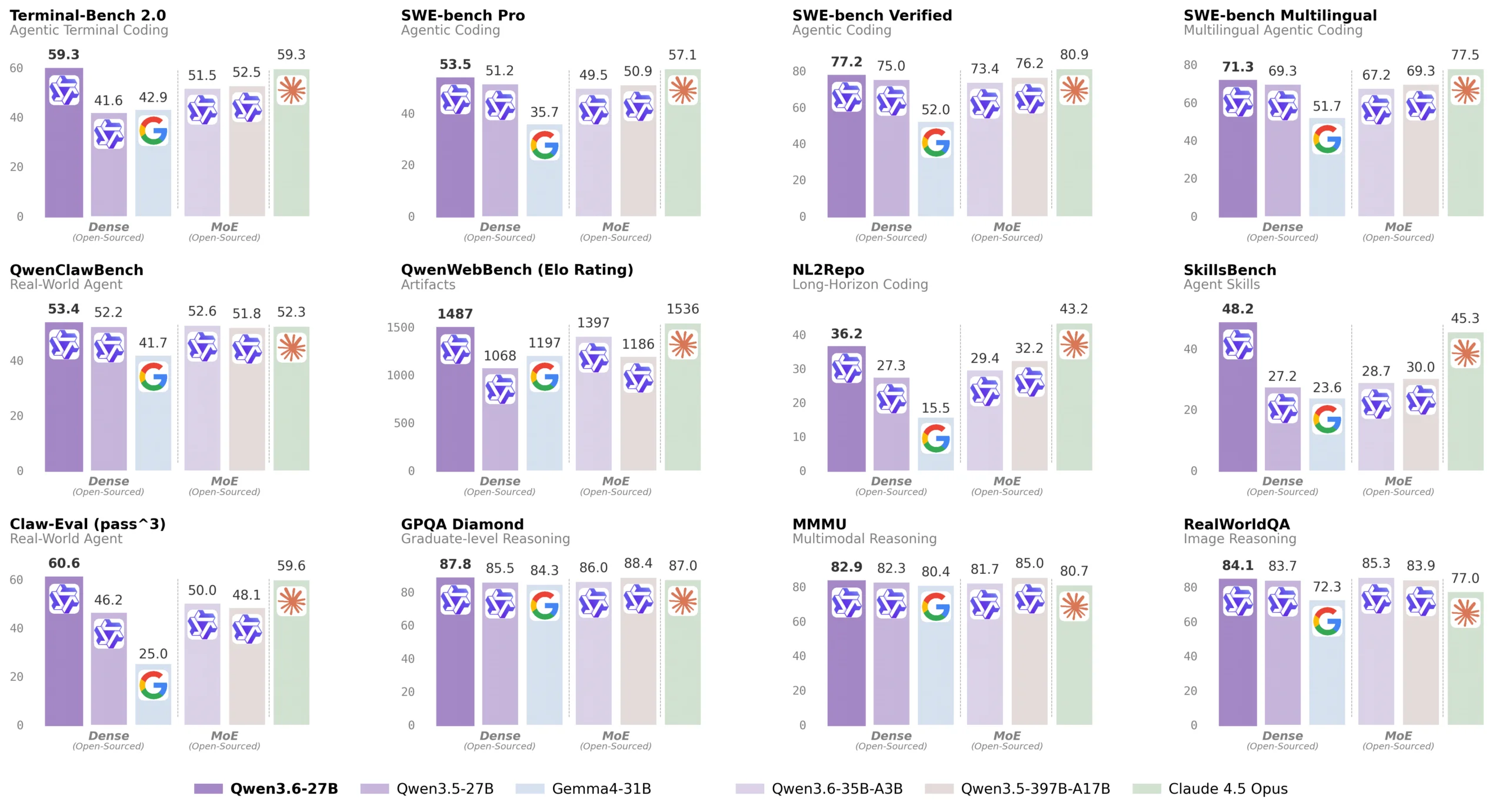
Alibaba の新型オープンソースモデル Qwen3.6-35B は、わずか 3 つのパラメータのみを活用しながら、Google Gemma 4 を SWE-bench で 73.4% vs 52.0% で上回る。オープンソース LLM の競争が激化。
オープンソース LLM の性能競争が加熱
Alibaba がリリースした新型オープンソースモデル Qwen3.6-35B が、Google の最新モデル Gemma 4 をコーディングベンチマークで大幅に上回ったことが明らかになった。Qwen3.6-35B は SWE-bench Verified で 73.4% に対し、Gemma 4 は 52.0% という大きな差が付いている。
さらに Terminal-Bench 2.0 でも Qwen3.6 は 51.5%、Gemma 4 は 42.9% とリードを維持。オープンソース LLM 市場における Alibaba の地位向上を示唆する結果だ。
Mixture-of-Experts で計算効率を実現
Qwen3.6 の強みは単なる性能だけではない。Mixture-of-Experts アーキテクチャを採用し、35 億個のパラメータのうちわずか 3 つのパラメータのみを各推論時に活用するという革新的な手法を導入している。これにより計算コストを大幅に削減しながら、高い推論品質を維持することに成功した。
推論タスクでは GPQA で 86.0% vs Gemma 4 の 84.3%、AIME26 では 92.7% vs 89.2% という結果となり、算術的推論能力でも優位に立っている。
マルチモーダル性能も視野に
Qwen3.6 は「思考モード」と「非思考モード」の切り替えが可能で、ユーザーのニーズに応じた柔軟な運用が実現できる。画像処理とビデオ処理の性能については「Claude Sonnet 4.5 と同等の水準を維持している」と Alibaba は主張しており、コーディングだけでなく広範な用途での活用を想定している。
Qwen Studio、Alibaba Cloud、Hugging Face、ModelScope など複数プラットフォームでの提供が開始されており、グローバルな開発者に対してアクセス障壁が低い設計となっている。オープンソース LLM 市場における Alibaba の挑戦が、Google や Meta が主導する競争構図に変化をもたらす可能性がある。