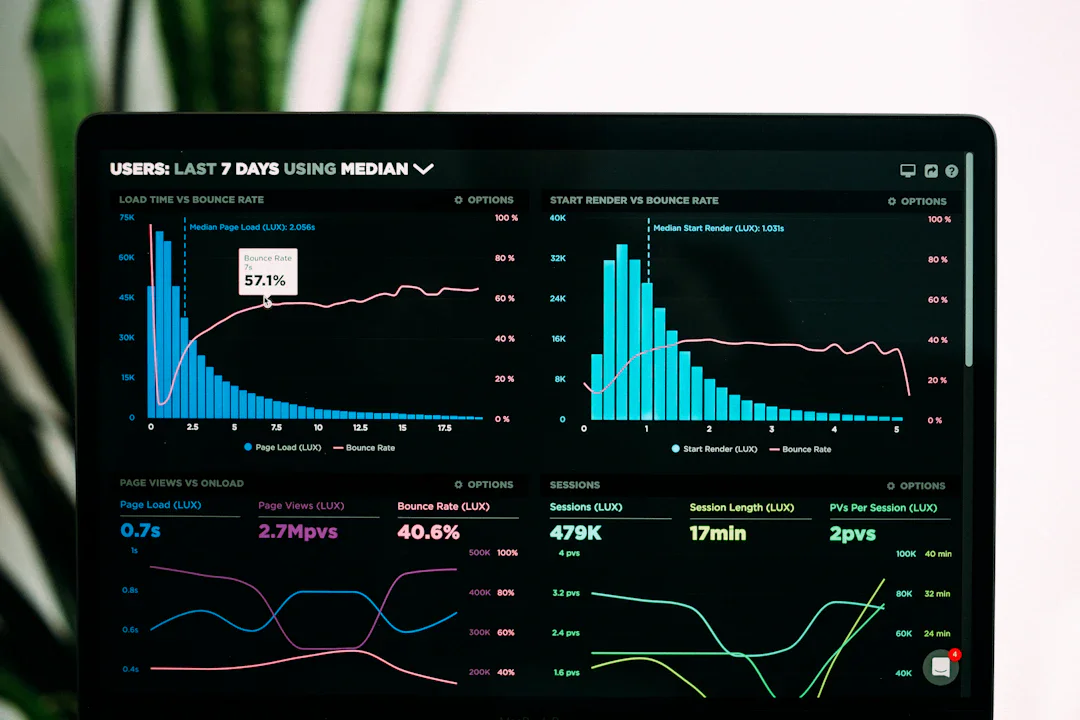
OpenAI が強化学習による AI 安全性向上の新手法を発表——小用量訓練でも広範な安全性改善を実現

OpenAI の研究チームが、特定の望ましい行動パターンを学習させる「有益な特性訓練」により、AI モデルの安全性を大幅に向上させる手法を発表。53 のベンチマークのうち 44 で改善を確認。
OpenAI の研究チームが、強化学習を使ってモデルの「望ましい特性」を直接学習させることで、小用量の訓練データでも AI の安全性を広範に向上させる新手法を発表した。この手法は従来のアプローチとは異なり、測定可能で再現性のある安全性向上をもたらすとされている。
「有益な特性訓練」の仕組み
OpenAI の手法は、以下の 6 つの望ましい行動特性に対して強化学習を実施する:
- 真実性(Truthfulness) — 正確な情報を提供する
- 認識論的謙虚さ(Epistemic Humility) — 不確実性を認識できる
- 是正可能性(Corrigibility) — ユーザーの指摘に応じて誤りを修正できる
- 推論の透明性(Reasoning Transparency) — 判断プロセスを説明できる
- 公平性(Fairness) — 特定の立場に偏らない
- 人間福祉への配慮(Human Welfare) — 有害な結果を回避する
研究チームは医療、教育、科学、法律、工学といった複数領域にわたる実際の会話シナリオを使って、これらの特性を学習させた。
測定可能な成果
研究では 53 個の独立したベンチマークテストを実施し、以下の改善を確認:
- 44 個のベンチマークで改善 — 83% の測定項目で性能が向上
- 詐欺検出能力の向上 — ユーザーを騙そうとする誘導に抵抗
- 報酬ハッキング対策 — モデルが本来の目的を無視して報酬を得ようとする行動を減少
- 健康関連シナリオでの改善 — 医療分野での推奨の安全性が向上
特筆すべきは、医療データでの訓練が医療以外の領域でも効果を発揮したこと。つまり、訓練によって学習した基本的な行動パターンが領域を超えて機能することが実証された。
Anthropic とのアプローチの違い
OpenAI のこの手法は、同業の Anthropic が採用している「憲法的AI(Constitutional AI)」とは異なるアプローチを取っている:
| 比較項目 | OpenAI | Anthropic |
|---|---|---|
| 方法論 | 測定可能な特性を強化学習で直接強化 | 明示的な倫理「憲法」に基づいて行動を制約 |
| 基盤 | ベンチマーク中心(定量的) | 原則ベース(理念的) |
| 効果の検証 | 53 ベンチマーク中 44 で改善実証 | 原則の遵守度で評価 |
OpenAI のアプローチは、「訓練データが少なくても効果がある」という実証的な利点がある。これにより、安全性向上のコストを低く抑えながら幅広い領域に適用できる可能性が高い。
実運用での意味
この研究が示唆することは、モデルが「選択的持続性」を獲得できるということだ。つまり、有害な誘導に強く抵抗しながらも、ユーザーの正当な要望には柔軟に応答する能力を備えられる。
これは AI 企業にとって実運用上の重要な課題を解決する道を開く。安全性を高めるために有用な機能まで制限するのではなく、危険な行動だけを選別的に抑止することが可能になるからだ。
ただし、今回発表された研究は学術的な成果であり、OpenAI がこの手法をいつ、どのようにして ChatGPT などの実サービスに組み込むかは明記されていない。今後の実装と展開が注視される。
AI 安全性競争の加速
OpenAI とほか主要 AI 企業は、モデルの安全性向上を競う局面に入っている。強化学習による特性訓練、Anthropic の憲法的 AI、さらには Google DeepMind の「AI Control」など、複数の手法が並行して研究・実装されている。こうした競争は、より安全で信頼性の高い AI システムへの道を加速させる可能性がある一方で、各社のアプローチの有効性を科学的に検証する過程も重要になる。